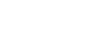

【儀表網 研發快訊】排序作為最基礎、最常用的計算范式之一,廣泛應用于人工智能、搜索引擎、路徑規劃、數據庫等眾多關鍵任務中。由于排序本質上的高度非線性,傳統硬件通常依賴復雜的比較器網絡和頻繁的主存訪問,在大數據時代愈發受限于帶寬、能效、面積瓶頸。近年來,存算一體技術被寄予厚望,尤其是基于憶阻器的存算一體架構,因其高密度、多電導態和高能效等突出優勢,已成為突破傳統“存算分離”架構瓶頸最具潛力的方向之一。然而,排序等非線性計算因其高度依賴復雜比較器網絡,一直被視為存算一體領域最難攻克的挑戰之一。


憶阻器存算一體排序系統整體示意圖
在這一背景下,北京大學信息工程學院/廣東省存算一體芯片重點實驗室楊玉超教授、陶耀宇研究員團隊在國際上首次實現了面向高復雜度排序任務的存算一體化硬件系統,提出了一個全新的、無需比較器的排序硬件架構,成功打破了存算一體技術難以處理排序等非線性計算的限制,標志著該領域實現從線性矩陣計算向非線性復雜任務的重大突破。相關研究成果以題為“A fast and reconfigurable sort-in-memory system based on memristors”的論文,近日發表在國際頂級期刊《自然?電子》(Nature Electronics)上。
在這項工作中,研究團隊首次構建了一個基于1T1R憶阻器陣列、無需比較器的存算一體排序軟硬件一體系統。該工作創新的提出了憶阻器陣列位讀取(Digit Read)機制,通過并行讀取從高位至低位逐步定位當前最小或最大值,配合存算一體電路,徹底顛覆了傳統基于比較-選擇的排序架構與流程。在此基礎上,研究團隊進一步提出了樹節點跳躍(Tree Node Skipping, TNS)排序算法及其硬件架構,利用遍歷路徑與信息復用,顯著減少了冗余操作,大幅提升了存算一體化排序效率。為應對更加復雜的實際排序應用場景,該工作還設計了三種跨陣列的擴展策略(Cross-array TNS, CA-TNS),分別面向不同并行維度:多陣列(Multi-Bank)策略支持大量數據按數分陣列進行并行處理,位分區(Bit-Slice)策略將位寬拆分到多個陣列實現數字流水并行,多電導(Multi-Level)策略則利用憶阻器的多電導態特性提升單元內并行度,三種創新策略可根據具體排序應用需求靈活配置、組合使用,形成了一套針對可變數據位寬的完整存算一體排序硬件加速方案。
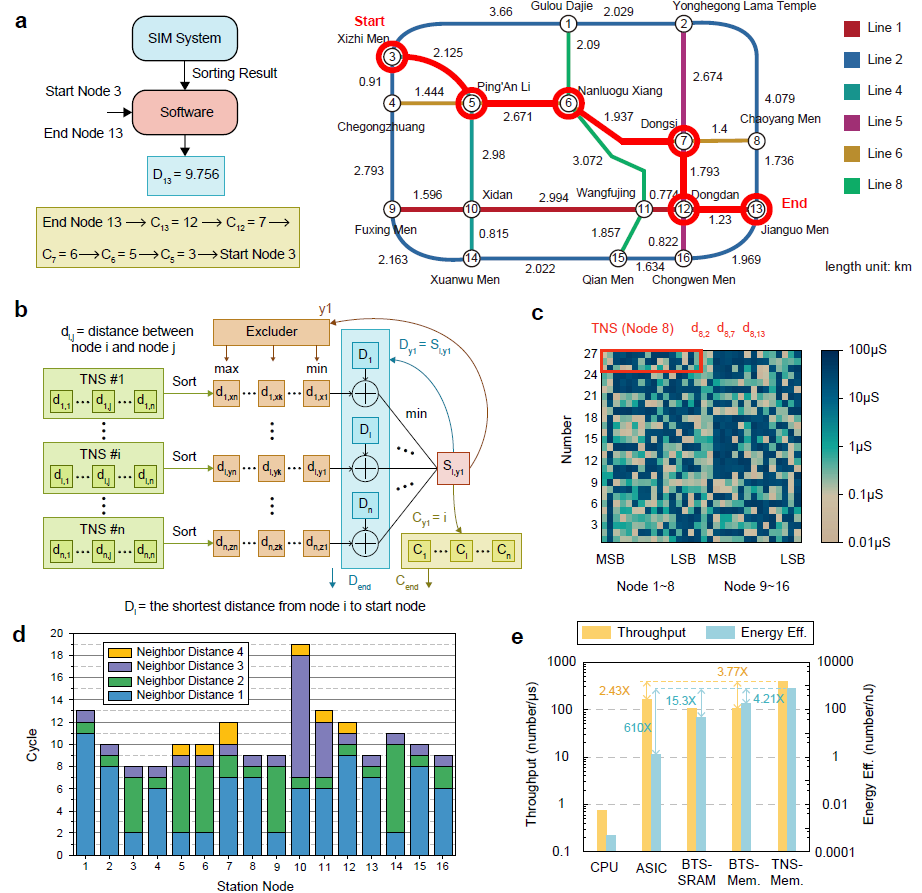

存算一體排序系統實現高效路徑規劃
該系統基于實際流片的憶阻器芯片,結合PCB與FPGA搭建了端到端的板卡級應用演示系統,全面驗證了其在多種典型排序任務中的優越性能。實驗結果顯示,相較于當前主流ASIC排序系統,該系統在5類代表性數據集上實現了高達7.70倍的速度提升、160.4倍的能效提升和32.46倍的面積效率提升,充分展現出存算一體架構在大數據排序場景中的巨大潛力。研究團隊進一步還將該系統應用于兩個實際任務中驗證了系統的實用性與通用性:在Dijkstra路徑規劃應用中,基于TNS排序系統成功實現了北京地鐵16個站點之間的最短路徑求解,不僅保持運算準確性,還大幅降低延遲和功耗;在神經網絡推理中,團隊將TNS與憶阻器矩陣向量乘法計算融合,在PointNet++網絡上實現了實時原位稀疏(run-time tunable sparsity),可根據推理精度需求靈活控制稀疏度,提升系統效率并同時降低計算開銷。相較于傳統ASIC排序系統,可以提升15倍的速度和67.1倍的能效。
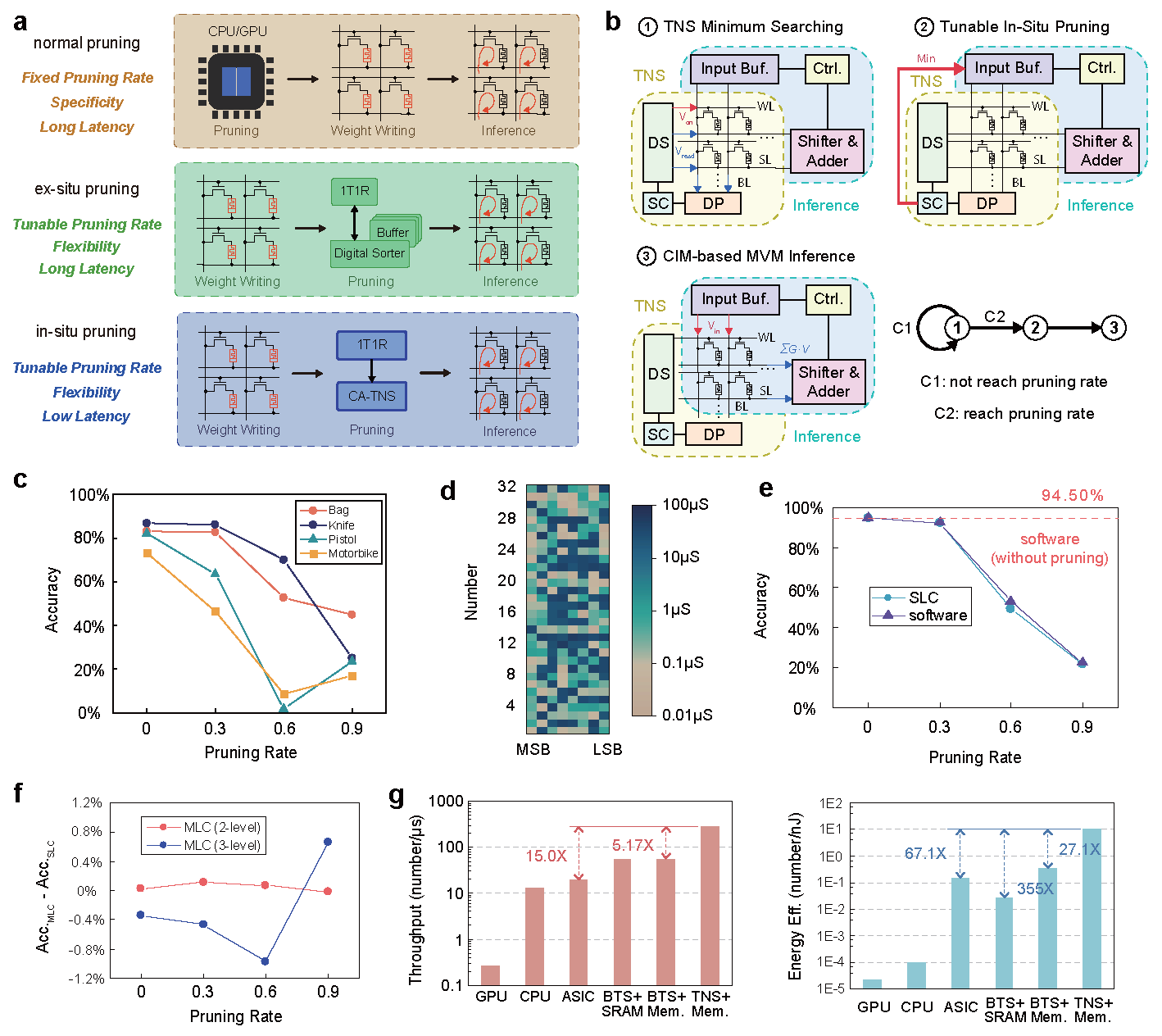
存算一體排序與現有矩陣存算一體計算兼容,實現實時可變稀疏AI計算
北京大學博士生余連風為第一作者,楊玉超與陶耀宇為通訊作者。相關工作得到了國家重點研發計劃、國家自然科學基金、廣東省存算一體芯片重點實驗室、北京市自然科學基金等項目的資助。




















所有評論僅代表網友意見,與本站立場無關。